I have been trying to get into Git for a while now, but with its lack (or terrible) support on Windows, I ignored it. I tried doing the stand alone CLI, but I don't like CLI, so I abandoned it. I tried using TortoiseGit, but wasn't too fond of still trying to get SHH or Putty integrated nicely. I want something that does it all for me, without me having to configure or do anything (or maybe I just completely did it wrong, or was using an old build). Along came GitExtensions in all its glory. It came packaged with everything I needed: Putty/SSH integration, repository management, GitHub support (remote features), and all the other awesome minor features. I mean it even has a CLI, if I ever wanted to use it.
The installation process was straight forward and painless. I will run you through the installation process and how to get GitExtensions working on Windows. Once done, you should be ready to dive into Git head on. I took the time to add screenshots of the installation process to aide you on.
Downloading
Well the first step of course is downloading the program. You can download it from the projects page. Personally I would go with the full installer (MSysGit, KDiff3 and PuTTy built in), so that you do not have to do all those separately yourself. Once downloaded, just execute the file and follow the steps.
Installation
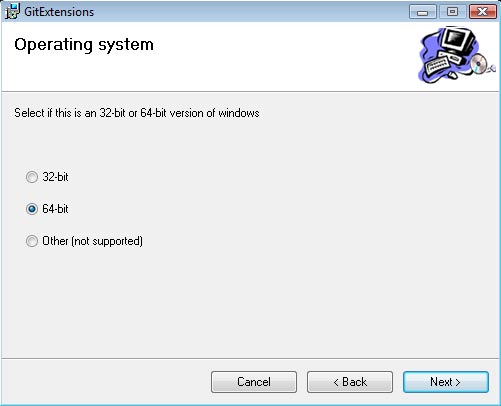
Its important that you go through the installer slowly, and select your proper configuration. For example, I am on a 64-bit computer, so I will be choosing the 64-bit option.
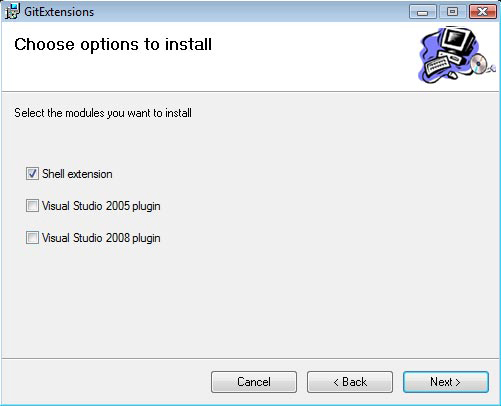
You should next be asked where to store the files, I kept them in its default location within the "Program Files". On the next screen it gives you a list of checkboxes for "Shell Extension" and "Visual Studio". If you are not going to be using the Visual Studio integration, do not check these boxes, however Shell Extension should be checked.
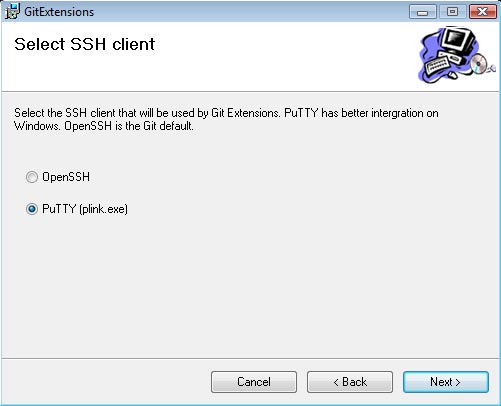
The next setting should be for your SSH support. Personally I have always used PuTTy, so I went with PuTTy (and the integration works perfect so far). If you are a fan of OpenSSH, then by all means go with what your comfortable and use to.
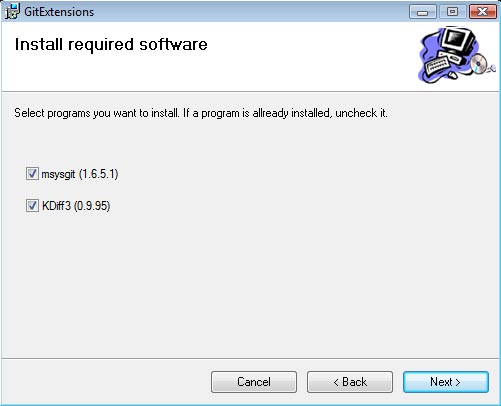
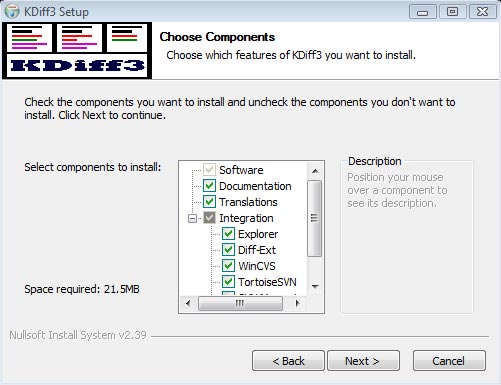
The final screen should be a list of required components to install. MSysGit is the base of Git, so make sure that it is checked off (if you already have it installed, you do not need to check it). KDiff3 is used for revision history allowing you to see changes, merges, etc between 2 file states. I have yet to use this feature, but its nice to have if you are working on a repository with multiple users. It also doesn't hurt to install it anyways. Once you are finished, click next to start the installation process.
During the installation process, it will prompt you to select your language, and will install the selected components. I kept all the default settings and locations for the KDiff installation, but you are welcome to change them.
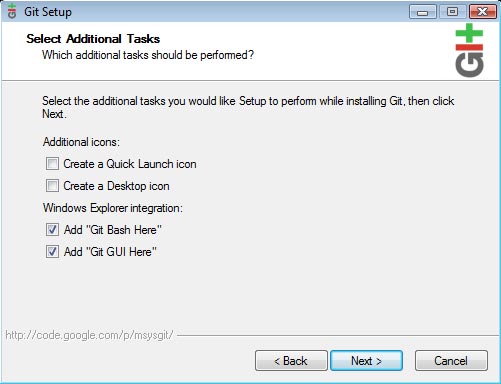
And finally, we get to install Git itself. You can just keep clicking "Next" to continue with the default installation. You will get to a screen with the options for "Add Git Bash Here" and "Add Git GUI Here". These settings add menus to your Windows Explorer right click menu, and will open up the CLI/GUI on the selected folder. They are not really mandatory, but its safe to keep them. The "Quick Launch" and "Desktop icon" checkboxes are not required, seeing as how we will never use Git stand-alone, but through GitExtensions, so you may uncheck them.
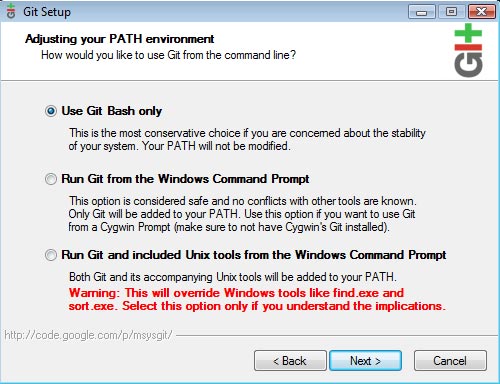
The next screen is important. You should keep "Use Git bash only" checked and not use the other options (unless you are familiar with these settings).
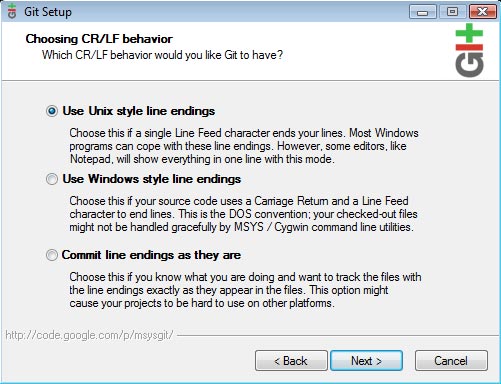
Git allows you to parse the correct line endings during each push. Personally I go with the "Unix style" line endings because my online servers are Linux boxes. These settings are entirely up to your environment, so choose which works best.
Completion
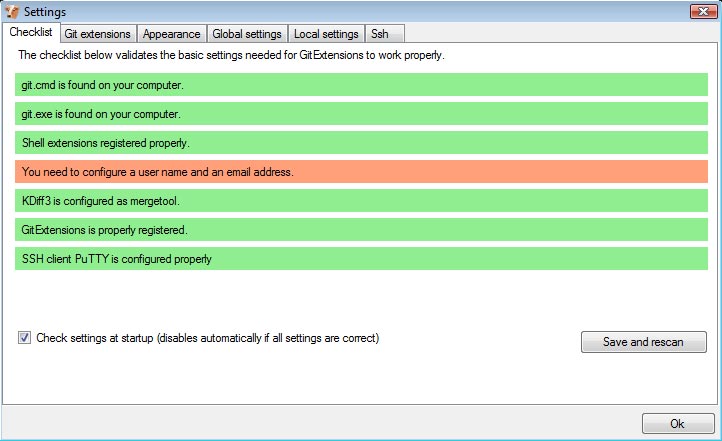
GitExtensions, alongside with MSysGit, KDiff and PuTTy should all be installed now. The next step is to launch GitExtensions and configure it to your needs. You should receive the following prompt.
All of the bars should be green if everything installed correctly, excluding the username/email bar. You will need to update the global settings with that information. You can do so by clicking on the orange bar, filling out the input fields and hitting OK. Once you have hit OK, you are finished, and a prompt will open up with buttons for "Open Repository", "Clone Repostory" and "Create Repository".
I hope this helped in your endeavor to use Git on Windows! I will discuss those 3 buttons in more detail within my next post. For the time being, everything should be installed correctly and you can begin messing around with GitExtensions. Enjoy!